System Overview
DataFed is a scientific data federation formed from a network of distributed services and data storage repositories that enable users to create, locate, share, and access working scientific data from any organization, facility, or workstation within the DataFed network. DataFed provides a software framework for the federation of distributed raw data storage resources along with centralized metadata indexing, data discovery, and collaboration services that combine to form a virtual “data backplane” connecting otherwise disjoint systems into a uniform data environment. Conceptually, DataFed is a modern and domain- agnostic “data grid” application with a host of advanced data management and collaboration features aimed at the open science and HPC communities.
DataFed features a robust and scalable centralized data indexing and orchestration service that ties potentially large numbers of independent DataFed data storage repositories together with high-performance data transfer protocols and federated identity technologies. This approach prevents the formation of independent “data silos” that suppress data discovery and access from outside of specific host organizations or domains - yet this architecture is scalable since data storage and transfer loading is distributed across many independently managed data repositories. Currently, DataFed’s central services are hosted within the Oak Ridge Leadership Computing Facility (OLCF) at the Department of Energy’s Oak Ridge National Laboratory (ORNL).
DataFed presents managed data using a logical view (similar to a database) rather than a direct physical view of files in directories on a particular file system. Data that is managed by a DataFed repository is maintained in system-controlled storage with no user-level file system access. This is to both protect the managed data from inadvertent changes or deletions, and to ensure that all data read/write operations go through a DataFed interface for proper system-wide coordination and access control. This approach is a step towards unifying and simplifying data discovery, access, and sharing - as well as avoiding the inherent entropy of traditional file systems that can lead to data misidentification, mishandling, and an eventual loss of scientific reproducibility.
Cross-Facility Data Management
Figure 1, below, shows a simplified representation of an example DataFed network consisting of the central DataFed services and several connected facilities and DataFed repositories. The enclosing gray boxes represent the physical boundaries of geographically distributed facilities. The wide blue arrows represent the DataFed high-speed raw data transfer “bus” (i.e. GridFTP) that is used to move data between facilities, and the green arrows represent the DataFed communication “bus” use by clients to send requests to DataFed.
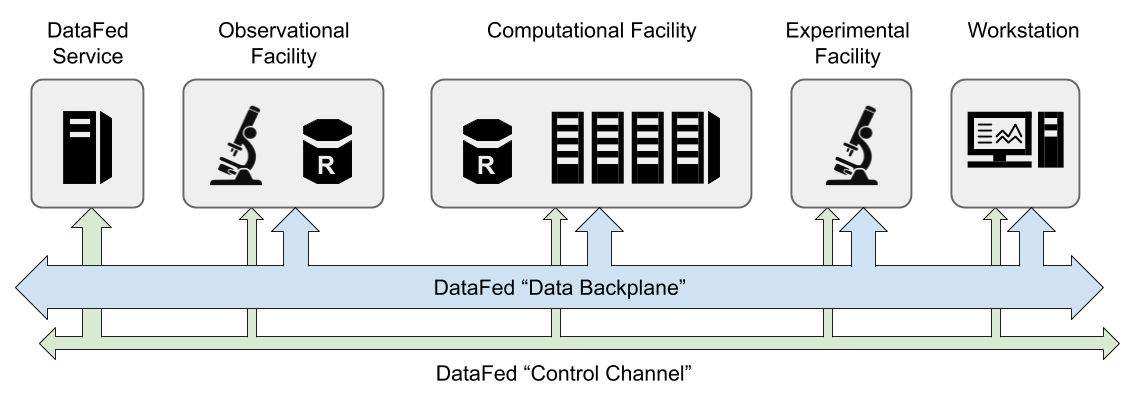
Figure 1 - An Example DataFed Network
In this example, there is an observational facility and a compute facility that each have a local DataFed data repository (a cylinder labeled with an ‘R’). Any facility in the system can read or write data from or to the data repositories in the observational or compute facilities (assuming proper access permissions); however, users within these two facilities will have lower latency access to the data stored there. In addition, independent workstations can also access data in these repositories - also assuming proper access permissions are granted.
When data is stored to a DataFed repository, Globus is used to transfer a user-specified source file (as a Globus path) into the repository where it becomes associated with a DataFed data record. Likewise, when data is retrieved from a DataFed repository, Globus is used to transfer the raw data of a DataFed record from the repository to a user- specified Globus destination; however, note that the raw data is simply copied - not moved - from the DataFed repository. The central DataFed service maintains data record tracking information and orchestrates raw data transfers, but never directly processes raw data.
Note
DataFed provides a universal storage allocation and fine-grained access control mechanisms to enable users at disjoint organizations to share and access data with each other without undue burden on local system administrators. Local administrators are able to maintain and enforce data policies on local DataFed repositories without disrupting remote DataFed facilities or users in any way.
Continuing with the previous example, the experimental facility shown does not have a local DataFed repository and, instead, could use allocations on the DataFed repository within the compute facility (if, for example, these facilities were collaborating or were managed by the same organization). In this scenario, users at the experimental facility would store and retrieve data using a DataFed allocation granted by the compute facility, but from the users perspective, all DataFed interactions would behave as if the repository were local. The only noticeable difference would be increased latency associated with DataFed data transfers.
Many cross-facility and collaborative research scenarios are supported by DataFed, and specific examples are discussed in the DataFed Use Cases document.
System Architecture
The DataFed system is composed of a number of system components and interfaces that are deployed across the DataFed network to implement scalable distributed data storage and indexing. A simplified system architecture is shown in Figure 2, below, and shows only the central DataFed services, one DataFed data repository, and supporting interfaces.
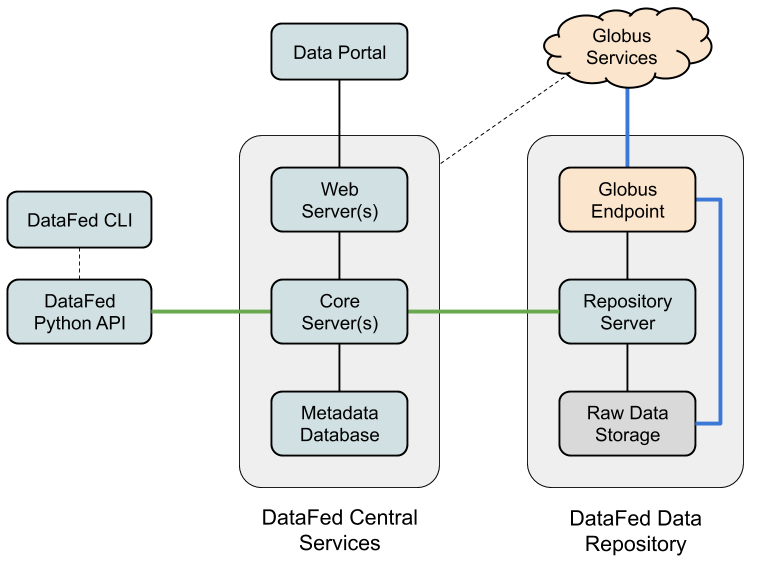
Figure 2 - DataFed System Components
DataFed’s central services include the “Core” service which is essentially the “brains” of DataFed. The core service manages the metadata associated with managed raw data and also implements access control, orchestration, and concurrency controls for data movements across the DataFed network. The core service, however, is not directly involved in the transfer of raw data - this function is delegated to Globus services, or more specifically, to the GridFTP servers (managed by GLobus) located at DataFed data repositories and other facilities. (The blue lines in Figure 2 indicate high-performance raw data transfer pathways.)
The raw data storage resources within a DataFed data repository can be any form of physical storage hardware, so long as the interface to this storage is supported by Globus. Currently this includes POSIX file systems and S3 object stores. The inherit reliability of the physical storage of a repository is determined by the host facility and could range from inexpensive magnetic disks to high-speed solid state drives or even archival-quality geographically distribute storage systems. Local administrators control repository policies and determine which DataFed users can utilize a repository by granting (or revoking) repository allocations. These local administrative policies and actions have no impact on DataFed on repositories at other facilities.
Figure 2 shows a DataFed repository in isolation; however, a host facility would typically integrate their DataFed repositories with their own local storage and compute resources. For example, a facility would likely have additional Globus endpoints that would mount the primary file system(s) of the facility, and they would install high-speed interconnects between the DataFed repository endpoint and the facility endpoint(s) to increase data transfer speeds between the two storage systems.
The web services within the DataFed central services primarily support a web portal that allows users to easily organize and share data from a web browser; however, the web services also play a critical role in authenticating DataFed users through Globus’ federated identity system (which is based on OAuth2). New DataFed users must register through the DataFed data portal and grant certain permission to DataFed through Globus’ authorization system. These permissions relate to user identification and enabling automatic data transfers on behalf of DataFed users.
Interfaces
Users are able to interact with DataFed through several available interfaces including a graphical web application, a command-line interface (CLI), and both high- and low-level application programming interfaces (APIs). The easiest way to interact with DataFed is through the web application (see DataFed Web Portal), and the web application is where users initially register for DataFed accounts.
The DataFed CLI and APIs are all provided through a single Python-based DataFed client packaged and available on PyPi. Refer to the Client Installation, CLI User Guide, and Python Scripting Guide for more information.
DataFed’s interfaces can be used from any workstation, laptop, or compute node; however, these interfaces only provide users with the ability to issue commands to the DataFed central service. If users need to be able to also transfer raw data to or from a given host machine, the local file system of the host machine must be connected to a Globus endpoint. Typically, research facilities will already provide Globus endpoints to access specific local file systems; however, for individual workstations and laptops, users will need to install Globus Personal Connect. See DataFed Client Installation </user/client/install> for more information.
User Accounts
User must register with DataFed in order to access public or shared data records and collections; however, registration is free and only requires a Globus account. (Refer to the /system/getting_started document for help with the registration process.) Once registered, users are tracked internally by their Globus identity but can also be searched for using their proper names. In order for users to be able to create their own data records, an allocation on one or more DataFed data repositories is required. Please contact the IT department at a DataFed-enabled facility for assistance with acquiring a DataFed repository allocation.
Note
In a future release of DataFed, a searchable directory of available data repositories will be made available and allow users to request allocations directly from within DataFed.
DataFed registration utilizes a standard Globus authentication and authorization process. When you begin the registration process from the DataFed welcome page, you will be redirected to Globus for authentication (log-in) using your Globus account. Globus will then ask you to authorize DataFed to access your Globus identity and to allow DataFed to transfer data on your behalf. Once this process is complete, you will be redirected to a DataFed post-registration page where you will create a DataFed password. This password is only used when manually authenticating from the DataFed command-line interface, and it can be updated from DataFed Web Portal at any time.
Note that DataFed will only initiate data transfers when you (or a process running as you) explicitly request it to. Further, DataFed data transfers are constrained to be between DataFed data storage repositories and Globus endpoints that you have pre-authorized (or “activated”) for access. Globus end-point activation is transient and access will expire within a period determined by the policies of the host facility.
System Concepts
DataFed provides a uniform, holistic, and logical view of the data, users, and various organizational structures associated with the federation of facilities and data storage resources that make up the DataFed network. From a users perspective, all data operations look and feel the same from within DataFed regardless of where DataFed is being accessed, where data is physically stored, or which DataFed interface is being utilized. In order to understand the features and capabilities of DataFed, as a whole, it is necessary to understand the underlying terminology and concepts, and these are discussed in this section.
Because DataFed relies heavily upon Globus for data transfers, it is helpful to understand the basics of how Globus works and how to use it to move data between Globus endpoints. A good starting point for understanding Globus can be found here.
Quick Reference
Below is a brief, alphabetical list of the most common DataFed terms and concepts. These topics are discussed in greater detail in following sections of this document.
Access Control - Access controls are sets of fine-grained permissions associated with data records and/or collections that may be applied to specific users or groups of users.
Administrator - A user designated by DOE/ORNL to have full access to DataFed administrative functions.
Aliases - An alias is an optional, human-friendly alternate identifier for data records and collections.
Allocation - An allocation is a storage allowance on a specific DataFed repository. One or more allocations are required in order to create DataFed data records.
Annotation - Annotations are a mechanism for opening and tracking issues associated with data records and collections. Depending on the severity and outcome of an issue, DataFed may propagate issues to downstream data records for further impact assessment.
Attributes - Attributes are searchable system-defined (fixed) metadata fields associated with certain entities (data records, collections, etc.) within DataFed. Textual attributes of data records and collections (ie. title, description) are full-text indexed. The term “attributes” is used to avoid confusion with optional user-defined “metadata”.
Catalog - The DataFed catalog is a categorized searchable index of internally “published” DataFed collections. All included collections and contained data records are readable by any DataFed user. The catalog system is intended for sharing working, rather than static, datasets.
Collection - A collection is a logical (or virtual) folder with a unique identifier and attributes that can be used to hierarchically organize, share, and download groups of data records and/or other collections.
Creator - The user that originally creates a Data Record becomes the owner (and creator) of the record and has full irrevocable access to the given record.
Data Record - A data record is the most basic unit of data within DataFed and consists of a unique identifier, attributes, and, optionally, raw data and domain-specific metadata.
Group - A group is a user-defined set of users for applying access controls to data records or collections. Groups are not the same as projects.
Identifier - Identifiers are system-unique alphanumeric strings that are automatically assigned to all entities within DataFed.
Metadata - The term “metadata” refers to optional searchable user-defined (domain-specific) structured metadata associated with data records. Required top-level metadata is referred to as “attributes” to avoid confusion.
Owner - The user or project that originally creates a Data Record becomes the owner of the record and has full access to the given record. Ownership can be transferred to another user or project.
Project - A DataFed project is a logical grouping of users to enable collective ownership of data and to simplify collaboration. Projects have their own data storage allocations.
Project Administrator - A user designated by a Project Owner to have managerial access to a specified project.
Project Owner - Any user that creates a DataFed Project is the owner, with full access rights, of the project.
Project Member - A user designated by either a Project Owner or Administrator to have member access to a specified project.
Provenance - Provenance is a form of metadata associated with data records that captures relationships with other data records. Provenance is maintained by DataFed using direct links between records rather than identifier references in record attributes or metadata.
Repository - A repository is a federated storage system located at a specific facility that stores the raw data associated with DataFed data records. Users and projects may be granted allocations on repositories to enable data storage.
Repository Administrator - A user designated by a DataFed Administrator to have managerial access to a data repository.
Root Collection - The root collection is a reserved collection that acts as the parent for all other (top-level) collections and data records. Each user and project has their own root collection.
Saved Query - A saved query is a data search expression that is stored in a query object such that it can be subsequently run by referencing the associated query identifier. The results of saved queries are dynamic (i.e. matches from when the query is run, rather than when it was saved).
Shared Data - When a user grants permission to access data records and/or collections to other users, those records and collections become visible to the referred users as “shared data”.
Tags - Tags are searchable, user-defined words that may be associated with data records and collections. Tags use is tallied internally to allow popular tags to be identified by users.
Task - Tasks are trackable background processes that run on the DataFed server for specific longer-running operations such as data transfers and allocation changes.
User - Any person with a DataFed account. Users are identified by their unique Globus ID account name, with optionally linked organizational accounts.
Identifiers and Aliases
All system “entities” in DataFed (data, collections, user, projects, etc.) are automatically assigned system-unique identifiers (IDs) consisting of a prefix (that determines entity type) followed by an alphanumeric value. For example, “d/12345678” would be an ID for data record, and “c/87654321” would be a collection. The numeric portion of these IDs is not in any particular order and can be considered essentially random, but unique for a given entity type. System IDs are not easy for humans to remember and use, thus for data records and collections (which are referenced frequently) users may opt to assign a human-friendly “alias” that can be used in place of the system identifier.
Aliases are lowercase alphanumeric strings that can contain the letters ‘a’ through ‘z’, the numbers ‘0’ through ‘9’, and the special characters ‘-‘,’_’, and ‘.’. Aliases can be considered to be the equivalent of a file or directory name in a file system. A scoping prefix is automatically attached to aliases in order to ensure aliases are unique across all users (and projects) in DataFed. These prefixes consist of the type of the alias owner (“u” for users, and “p” for projects), followed by the user or project ID, separated by colons. For example:
The alias "my.data" for user "u/user123" becomes "u:user123:my.data"
and
The alias "simulation.run.1" within project "p/stf123" becomes "p:stf123:simulation.run.1"
Note
In both the DataFeb web portal and the command-line interface, scoping prefixes are not required to be entered for aliases (nor are they displayed) except when referencing data owned by another user or project.
In general, aliases are intended to support interactive data browsing and sharing and, thus, should be easy to use and understand. Aliases should not be used to encode complex parameters or other information that is more appropriately placed in a data record’s searchable metadata. This is especially true when sharing data with users that may not be familiar with an ad hoc name-based parameter encoding scheme.
Note
Capturing and storing scientific parameters and other context as searchable, schema-based metadata results in data that is far more findable and interoperable than encoding this information in aliases.
Data Records
A data record is the basic unit of data storage within DataFed and consist of, at a minimum, an identifier and a title. A number of additional optional informational fields can be specified including an alias, a textual description, structured metadata, provenance relationships, and tags. All of these data record fields are maintained centrally within DataFed and do not count against a users storage allocation(s). Refer to the Field Summary, below, for a full list of data record fields.
While metadata-only data records can be useful for specific use cases, it is likely some form of source data will need to be associated with a given data record. This data is referred to as “raw data” because DataFed treats it as an oblique attachment to a data record (i.e. DataFed cannot “see” inside this raw data for purposes of indexing or searching). Raw data can be any format and any size so long as a user has sufficient allocation space to store it. See the Raw Data section, below, for further details.
When creating a data record, a storage allocation on a DataFed repository must be available. If a user has multiple allocations, then an allocation can be specified or the default allocation will be used instead. The default allocation can be viewed and set in the DataFed web portal. After creation, it is possible to move a record to an allocation on a different repository, and if raw data has been uploaded it will be relocated automatically. Similarly, data record ownership can be transferred to another DataFed user or project, and again, raw data will be relocated.
Note
If large collections of data records are moved between allocations, or to new owners, the server-side background task associated with moving the raw data may take a significant amount of time to complete. Progress can be monitored via the web portal or the CLI.
Metadata
The metadata of a data record is distinct from the built-in record fields such as title and description, and is represented using Javascript Object Notation (JSON). JSON was selected because it is human-readable, can represent arbitrary structured documents, and is easily validated using JSON-based schemas (see https://json-schema.org/). Like other fields, metadata is searchable using the powerful built-in query language described in the Data and Collection Search section of this document.
When creating or updating a data record, metadata may be directly specified or a JSON file may be referenced as the metadata source. When updating the metadata associated with an existing data record, the user has the option to either replace all of the existing metadata or to merge new metadata with existing metadata. In the case of merging, any keys that are present in both the new and existing metadata will be overwritten by the new values - other existing keys are left unchanged and new keys are inserted.
Note
When providing metadata, it must fully comply with the JSON specification, located at https://tools.ietf.org/html/rfc8259.
Provenance
Provenance information in DataFed is maintained as direct links between any two data records, and includes a direction and a type. Currently three types of provenance relationships are supported, as shown in the table below. The direction of provenance relationships is implicitly defined by setting relationship information on “dependent” data records only.
Relationship |
|---|
Is Derived From |
Is a Component Of |
Is a Newer Version Of |
It is easy to understand provenance direction by thinking of the dependent record as the subject of the relationship statement. For example, if data record “xyz” “is derived from” data record “pqr”, then data record “xyz” is the dependent and the provenance relationship to record “pqr” should be set on record “xyz”.
Raw Data
Raw data is associated with a DataFed data record by uploading a source file from a Globus endpoint, and, once uploaded, it can be downloaded to any other Globus endpoint. Users uploading and/or downloading raw data must have appropriate permissions both on the source/destination Globus endpoints and on the DataFed record itself. When data is uploaded to a data record, the source path, extension, and data size is captured in the data record. When downloading, users can request either the original filename or the record identifier be used as the name for the downloaded file.
Note
As with all Globus transfers, it is the users responsibility to ensure that the source or destination endpoints are activated prior to initiating a raw data transfer in DataFed. This restriction is due to the inherent security design of Globus, which prohibits agent processes, like DataFed, from activating endpoints on behalf of users. Note, however, that DataFed data repositories never require activation.
When a raw data transfer is initiated from DataFed, the transfer can be monitored in DataFed using the “Task ID” of the transfer request. In the DataFed CLI and Python API, the task ID is provided in the output of the request. In the DataFed web portal, the most recent tasks will be shown and periodically updated under the “Tasks” tab. When a transfer completes without errors, the task status will become “SUCCESS”; otherwise an error message will be provided. Common problems include forgetting to activate an endpoint, endpoint activation expiring, or referencing an invalid path or filename.
Field Summary
The table below lists all of the fields of a data record. Most of these fields are searchable using simple equality tests (i.e. == and !=); however the title and description fields are full-text indexed - enabling root-word and phrase searches as well. When composing search expressions, the field names as shown in the third column of the table must be used. User-specified metadata fields can be searched by prefixing the field names in the associated JSON document with “md.”.
Field |
Type |
Name |
Description |
|---|---|---|---|
ID |
Auto |
id |
Auto-assigned system-unique identifier |
Alias |
Optional |
alias |
Human-friendly alternative identifier |
Title |
Required |
title |
Title of record |
Description |
Optional |
desc |
Description of record (markdown allowed) |
Tags |
Optional |
— |
Tag list |
Metadata Schema |
Optional |
schema |
Schema ID for metadata |
Metadata |
Optional |
md.* |
User-specified JSON document |
Provenance |
Optional |
— |
Relationship(s) with other data records |
Allocation |
Default |
— |
Data repository ID of allocation used |
Owner |
Auto |
owner |
User ID of current record owner |
Creator |
Auto |
creator |
User ID of original record creator |
Source |
Auto |
source |
Globus path of source raw data |
Size |
Auto |
size |
Size of raw data, in bytes |
Ext |
Optional |
ext |
Extension of raw data file |
Create Time |
Auto |
ct |
Creation timestamp (Unix) |
Update Time |
Auto |
ut |
Update timestamp (Unix) |
Collections
Collections in DataFed are a logical mechanism for organizing, sharing, and downloading sets of data records. Data records may be placed in multiple collections (as links) and child collections may be created to further organize contained records. Like data records, collections have, at a minimum, an identifier and a title, but additional optional fields may be defined including an alias, a description, public access, and tags. Unlike data records, collections do not support user-specified structured metadata.
Collections do not exclusively “own” the data records contained within them, but certain collection operations will directly impact the records (and child collections) within them. There are also constraints on which data records can be placed in a collection. These operations and constraints are as follows:
Permissions - Collections allow inheritable permissions to be set that apply to all contained data records and child collections. This is generally the preferred way to share data other users and to control data access within a project.
Single Owner - It is not currently possible to mix data records owned by multiple users in a single collection. Only data records owned by the user that also owns the collection can be linked (this applies to project collections as well). However, this restriction does not apply to record “creators”.
Deletion - If a collection is deleted, all child collections, as well as all data records that exist only within the deleted collection hierarchy, will be deleted.
Downloads - Downloading a collection will download all raw data associated with contained data records - including those in child collections. Downloaded raw data will all be placed in the same user-specified destination path (without subdirectories). The DataFed web portal will display download dialog with a selectable list of which data records to download from the collection.
Allocation Change - Collections can be used to change the repository allocations of all contained data records. Any contained data record that is not already on a specified target allocation will be scheduled to be moved. Those that are already on the target allocation will be ignored. Currently, this operation can only be done in the DataFed web portal.
Ownership Change - Collections can be used to change the ownership of contained data records. All records are moved to a specified target collection owned by the new owner, and the all associated raw data will be scheduled to be moved to the new owner’s default allocation. Currently, this operation can only be done in the DataFed web portal.
Root Collection
All users and projects own a special “root” collection that acts as the parent for all other (top-level) collections and/or data records. The root collections behaves like a normal collection except that it cannot be edited or deleted. The root collection also has a special identifier and alias which are derived from the type and owner identifier, as follows:
For a user with an ID of "user123", the root collection ID is "c/u_user123_root" and the alias is "u:user123:root"
For a project with an ID of "proj123", the root collection ID is "c/p_proj123_root" and the alias is "p:proj123:root"
Public Collections
Collections can be set to public access, in which case the collection and all of its contents will become discoverable and readable by any DataFed user. Public access is implemented through a DataFed catalog system which allows users to browse and search for public collections and datasets. Please refer to the Catalog section for more information.
Field Summary
The table below lists all of the fields of a collection. Currently, only public collections in the DataFed catalog can be searched, and only through the DataFed web portal. In a future release, direct queries will be supported.
Field |
Type |
Name |
Description |
|---|---|---|---|
ID |
Auto |
id |
Auto-assigned system-unique identifier |
Alias |
Optional |
alias |
Human-friendly alternative identifier |
Title |
Required |
title |
Title of record |
Description |
Optional |
desc |
Description of record (markdown allowed) |
Tags |
Optional |
— |
Tag list |
Access |
Default |
— |
Public or private (default) access |
Category |
Optional |
— |
Catalog category for public access |
Owner |
Auto |
owner |
User ID of current collection owner |
Creator |
Auto |
creator |
User ID of original collection creator |
Create Time |
Auto |
ct |
Creation timestamp (Unix) |
Update Time |
Auto |
ut |
Update timestamp (Unix) |
Projects
A DataFed project is a distinct organizational unit that permits multiple users to create and manage data records and collections as a team - without requiring project members to maintain their own complex access control rules. Projects can be created by any DataFed user, but a DataFed repository allocation is required for the project before any data records can be created within, or transferred to, the project. Projects have specific user roles with distinct permissions, as follows:
Project Owner - The user that initially creates a project becomes the owner and has complete control over the project and contained data and collections. The owner can add and remove project members and administrators.
Administrators - These users have the ability to add and remove project members (but not other administrators), and can also configure access control rules on the projects root collection.
Members - These users may create and update data records and collections based on the access control rules set by the project owner or administrators. Members always have administrative access to records they create.
When any user associated with a project creates a data record or collection inside a project, the project, rather than the creating user, becomes the owner of the new record or collection. While users still have administrative control over records and collections they create within a project, the allocation of the project is used to store and manage any raw data associated with these records.
Access Controls
DataFed implements fine-grained access control through a set of permissions that can be applied to both data records and collections. Permissions can be configured to apply to specific users, groups of users, or a combination of these, and define what specific actions users can take. Collections also allow specification of inherited permissions that are applied to items linked within it. The individual permissions are as follows:
READ RECORD - Allows reading basic information about a data record or collection.
READ METADATA - Allows reading structured metadata of a data record.
READ DATA - Allows downloading raw data from a data record.
WRITE RECORD - Allows updating basic information of a data record or collection.
WRITE METADATA - Allows updating structured metadata of a data record.
WRITE DATA - Allows uploading raw data to a data record.
LIST - Allows listing of items linked within a collection (does not imply reading these items)
LINK - Allows linking an unlinking items to/from a collection
CREATE - Allows new items to be created within a collection
DELETE - Allows deletion of records and collections
SHARE - Allows setting access controls on records and collections
LOCK - Allows locking a record or collection to temporarily suppress all permissions
Multiple user- and group- scoped permissions may be applied. Permissions for a given user are evaluated by combining all permissions set for all scopes that apply - including permissions that may be inherited from parent collection hierarchies. Because permissions are inherited and additive, the absence of a permission on a given data record or collection is not equivalent to denying that permission.
Access controls are typically applied to parent collections of a collection hierarchy where contained data and sub-collections inherit the permissions defined by the top-level parent. Collections have both “local” and “inherited” permissions; where local permissions control access to the collection record itself, and “inherited” permissions are the permissions passed down to all contained data records and sub-collections. Note that because data records can be placed into multiple collections, the inherited permissions of all associated parent collections are evaluated for each user accessing a given data record.
Repository Allocations
Having access to DataFed does not, in itself, grant users the ability to create or manage data within DataFed. This is because DataFed does not provide any raw data storage on its own, but instead relies on federated storage provided by DataFed member organization and/or facilities. Federated storage is implemented through a network of geographically distributed “data repositories” that are owned and maintained by specific member organizations, yet are potentially accessible by any DataFed user.
Typically, DataFed users with an account at one or more DataFed member facilities will be automatically granted storage allocations on data repositories managed by the organization that operates the facilities. For unaffiliated users, storage allocations may be explicitly requested from a DataFed member organizations. DataFed member organizations are free to define and enforce their own data storage policies; therefore, users wishing to acquire storage a specific allocation must contact the associated organization for information on how to gain access. Even though unaffiliated users with no storage allocation cannot use DataFed to create and manage their own data, DataFed still allows these users to locate, access, and monitor data owned by other DataFed users or projects.
It is likely that DataFed users may have multiple storage allocations on different data repositories. In this case, a default storage allocation may be specified, or a specific storage allocation selected when creating new DataFed data records. Data can be accessed in a consistent manner no matter which data repository it is stored on; however, the physical proximity of a data repository in relation to the point of use of data can impact access latency.
Metadata Schemas
Metadata schemas are documents that define and validate the allowed fields and field types of the domain-specific metadata associated with data records. Schemas can be used to constrain the values of fields, including min/max values, numeric ranges, or text patterns, and can also define conditional constraints. Existing schemas can be referenced by new schemas as a sub-document, or as a custom type for a local field. When a defined schema is associated with a data record, the domain- specific metadata of that record is validated against the schema, and if any errors are found, the data record is flagged and the validation errors are stored with the data record for subsequent review. Optionally, a flag can be used in the DataFed CLI/API to reject data record create or update requests if the associated metadata does not validate against a specified schema.
In DataFed, the metadata schema implementation is based on a modified version of the JSON Schema Specification, version ‘2020-12’, available at https://json-schema.org/. The primary difference between DataFed’s schema implementation and the standard is how schemas are identified and referenced. With the official JSON schema specification, schemas are both identified and accessed via URIs. This approach allows arbitrary storage, distribution, and reuse of schemas; however, it also introduces significant latency and resource costs within DataFed services. For this reason, DataFed instead stores all schemas locally and restricts schema references to local schemas only. However, external schemas can still be imported into DataFed and can then be referenced with a local identifier.
Annotations
Annotations are a feature that allows users (with proper permissions) to attach general notifications, questions, warnings, and errors to data records. Annotations have several states including “open”, “active”, and “closed”. When an annotation is initially created, it is in the “open” state by default and only the owner/creator of the data record and the author of the annotation will be able see the new annotation. A mechanism is provided to allow the two parties to exchange information, and if deemed suitable by the owner of the data record, the annotation can be “activated” which will make it visible to all users that have access to the associated record.
In addition, if a record has dependent records (via provenance references) and an error or warning annotation is activated, then the dependent records will have new annotations automatically created with links to the parent annotation. The owners of the dependent records will then have an opportunity to perform an impact assessment and either close or activate the derived annotations. This process continues down the provenance relationships as each derived annotation is activated. This mechanism enables a form of data “quality assurance” even when the data producers and data consumers are unknown to one other.
In a future release, users will be notified via email when annotations associated with owned or derived records are created or updated.
Data and Collection Search
DataFed provides a powerful search feature that allows data records and collections to be found within a users personal data space, across projects, and data/collections shared by other users and/or projects. Searches can be saved and will then be accessible via the “Saved Queries” feature in the DataFed web portal, the command-line interface, and the Python API. Below is a list of fields that can be used for searches and saved queries.
ID/Alias - A full or partial ID or alias with wildcard support
Text - Word/phrases within title and/or description (full-text indexed)
Tags - Assigned tags
Date / Time - “From” and “To” date ranges based on record update timestamp
Creator - Creators user ID
Metadata Schema - Metadata schema ID
Metadata Query - Domain-specific metadata query expression (schema-aware query builder provided)
Metadata Errors - Finds records with metadata schema validation errors
Catalog
The DataFed catalog allows collections and data records to be internally published (without DOI numbers) for use by any DataFed user. The catalog allows users to browse collections by hierarchical categories and to search for collections and datasets directly by filtering relevant field and metadata schema values.