Basic Usage¶
TX2 consists of two classes: tx2.wrapper.Wrapper
and tx2.dashboard.Dashboard.
The wrapper class wraps around the transformer/classification model and acts as an interface between the dashboard and the transformer. The wrapper is in charge of computing and caching all the necessary data for the dashboard visualizations.
The dashboard class handles setting up and rendering the widget layout and handling dashboard interactivity.
Note that this dashboard is primarily for exploring how a transformer responds to a test set of data, and the larger this test set, the slower the dashboard may respond and the longer the wrapper’s pre-computation steps will take.
The flow of interactions between this library and a jupyter notebook is shown below:
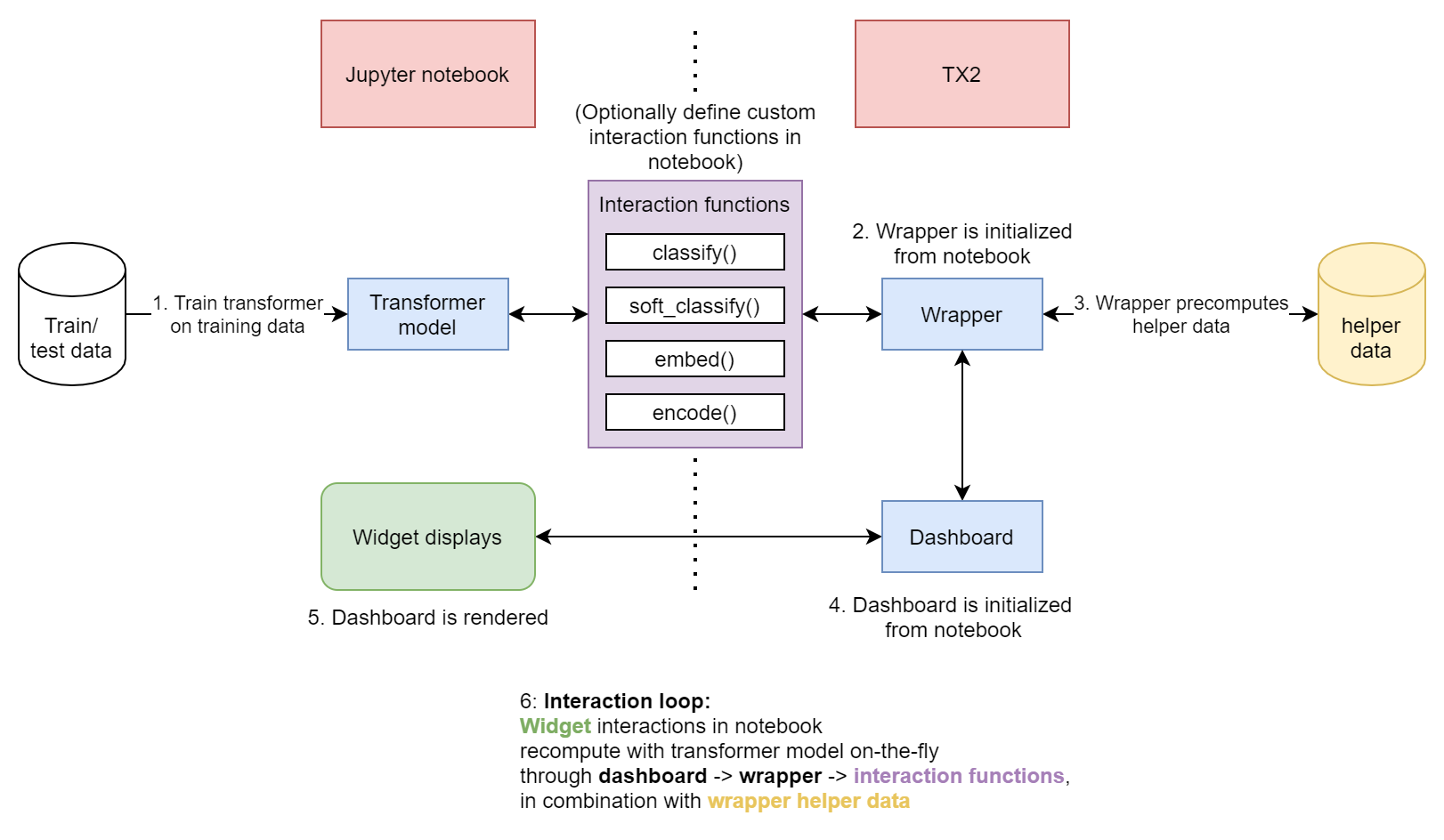
All communication between TX2 and the transformer is done entirely through a set of four interaction functions, discussed further in the sections below.
Wrapper Setup¶
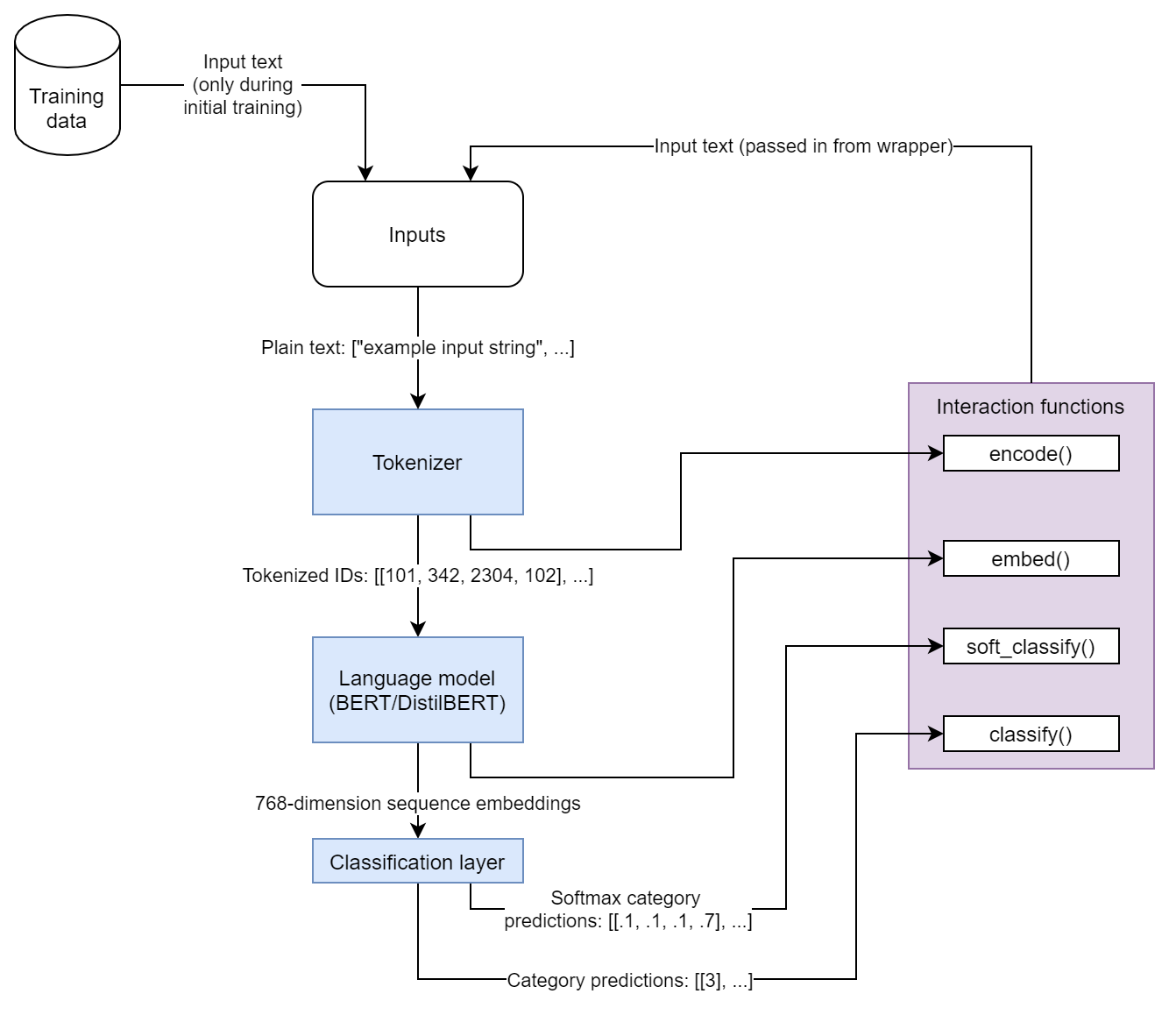
There are two different general approaches for setting up the transformer wrapper, depending on the level of customization needed to suit your model. The wrapper relies on four different functions for computation:
An embedding function - returns a single sequence embedding for each input text.
A classification function - returns the predicted output class for each input text.
A soft classification function - returns some output value for each class for each input text (essentially a non-argmaxed classification output.)
An encoding function - converts text into inputs the model is expecting.
In all cases, the wrapper is instantiated, and then the wrapper’s prepare() function
must be called. This runs through all necessary data computations that the
dashboard relies on.
An example diagram of a transformer model that provides the expected data for each of these functions is shown here:
Default Approach¶
In the default approach, defaults for the four functions are already handled internally, and
rely on directly passing the necessary model pieces to the wrapper
constructor. There are three pieces the constructor expects for this
to work correctly:
A huggingface tokenizer (the default encoding function will call
encode_pluson this tokenizer)A calleable huggingface language model (the default embedding function will take the final layer outputs of this for the first token, expected to be a
[CLS]token. Importantly, this means by default it expects a BERT transformer. Any other type will require using the custom approach below)A calleable classifier that returns an output value for each class (this is directly used for the default soft classification function, and the default classification function argmaxes the output.)
An example model that would work in this approach is shown below, as in the first example notebook:
import torch
from transformers import AutoModel
class BERTClass(torch.nn.Module):
def __init__(self):
super(BERTClass, self).__init__()
self.language_model = AutoModel.from_pretrained("bert-base-cased")
self.classification_head = torch.nn.Linear(768, 20)
def forward(self, ids, mask):
output_1 = self.language_model(ids, mask)
output = self.classification_head(output_1[0][:, 0, :])
return output
To instantiate the wrapper, we pass in the data and necessary model pieces, and then call
prepare() to run the necesary computations and cache the results.
from transformers import AutoTokenizer
from tx2.wrapper import Wrapper
# initialize
model = BERTClass()
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
train_df, test_df, encodings = # load dataframes and encodings dictionary
# train model
# create wrapper
wrapper = Wrapper(
train_texts=train_df.text,
train_labels=train_df.target,
test_texts=test_df.text[:2000]
test_labels=test_df.target[:2000]
encodings=encodings,
classifier=model,
language_model=model.language_model,
tokenizer=tokenizer)
wrapper.prepare()
Note that in the example above, we expect the dataframes to have a “text” column that contains the
input text, and a “target” column that contains the integer target class. encodings is a
dictionary that contains class labels/names as keys, with each value as the integer representation for it,
e.g. for the 20 newsgroups dataset:
{
'alt.atheism': 0,
'comp.graphics': 1,
'comp.os.ms-windows.misc': 2,
'comp.sys.ibm.pc.hardware': 3,
'comp.sys.mac.hardware': 4,
'comp.windows.x': 5,
'misc.forsale': 6,
'rec.autos': 7,
'rec.motorcycles': 8,
'rec.sport.baseball': 9,
'rec.sport.hockey': 10,
'sci.crypt': 11,
'sci.electronics': 12,
'sci.med': 13,
'sci.space': 14,
'soc.religion.christian': 15,
'talk.politics.guns': 16,
'talk.politics.mideast': 17,
'talk.politics.misc': 18,
'talk.religion.misc': 19
}
Custom Approach¶
If a different type of transformer or different way of constructing your model makes any of the default functions infeasible or incorrect, it is possible to manually specify any of the four functions the wrapper relies on. This can be done by defining the function and then assigning it to the corresponding wrapper attributes:
As an example, one could change the embedding mechanism to average the output token embeddings rather than
expecting a [CLS] token.
import numpy as np
transformer = # load/train language model
def average_embedding(inputs):
return np.mean(transformer(inputs['input_id'], inputs['attention_mask'])[0])
wrapper = Wrapper(...)
wrapper.embedding_function = average_embedding
wrapper.prepare()
Note that while the wrapper’s embed(), classify(), and soft_clasify()
all take an array of texts as input, the corresponding backend wrapper attributes are functions
that expect encoded inputs, as returned from tx2.wrapper.Wrapper.encode_function.
By default, if you do not specify a custom encode_function, the wrapper runs encode_plus
on the tokenizer specified in the constructor with the tx2.wrapper.Wrapper.encoder_options passed in.
The results are returned in a dictionary with "input_ids" and "attention_mask" as keys.
Depending on what custom functions you define determines which model pieces you do or do not need to pass to the constructor:
If you define a
encode_function, you do not need to pass anything totokenizer.If you define a
classification_functionandsoft_classification_function, you do not need to pass anything toclassifier.If you define a
embedding_function, you do not need to pass anything tolanguage_model.
Input Data Flow¶
To help understand how custom functions fit in, below is an example of how data is converted and passed through
the wrapper when the wrapper’s classify() is called.
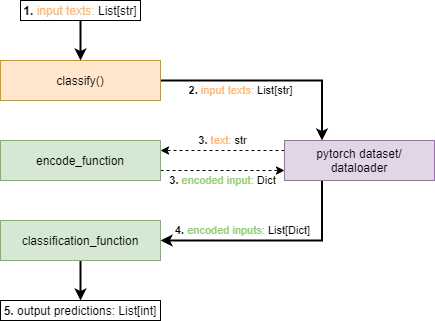
The
tx2.wrapper.Wrapper.classify()function is called with an array of texts.The input texts are placed into a pytorch dataset child class and dataloader.
For each input text the dataset calls the
tx2.wrapper.Wrapper.encode_function.For each batched set in the dataloader (containing the outputs from 2), the batch array of encoded inputs are passed into
tx2.wrapper.Wrapper.classification_function.Output predictions are aggregated and sent back up/returned from the
classify()call.
Dashboard Setup¶
The dashboard class is relatively straight forward - initialize it with the prepared transformer wrapper and any
settings for which sections to display, make any desired widget alterations, and then call render()
or manually pull the components and directly display them with IPython.display.display(). (For more details see the
Dashboard Widgets.)
from tx2.wrapper import Wrapper
from tx2.dashboard import Dashboard
# load and train transformer and data
wrapper = Wrapper(...)
wrapper.prepare()
dash = Dashboard(wrapper)
dash.render()
The dashboard constructor contains six booleans which control what sections get displayed when you call render():
class Dashboard:
def __init__(
self,
transformer_wrapper: wrapper.Wrapper,
show_umap=True,
show_salience=True,
show_word_count=True,
show_cluster_salience=True,
show_cluster_sample_btns=True,
show_wordclouds=False,
):
The show_wordclouds option is False by default as the cluster-based show_word_count and
show_cluster_salience tend to convey more useful and representative information than the wordclouds.
Tips¶
Note that for the plots to display correctly, you need to run the %matplotlib agg or %matplotlib inline magic.
For the matplotlib plots themselves to remain interactive (with zoom/pan controls), you can instead use
%matplotlib notebook. To remove the headers from each figure, you can run an HTML magic block to magic
them away:
%%html
<style>
div.ui-dialog-titlebar {display: none;}
</style>
Sometimes with %matplotlib inline, various graphs will duplicate every time they’re re-rendered, which can
be fixed by calling plt.ioff() or using %matplotlib agg instead.