|
Doxygen
1.9.1
Toolkit for Adaptive Stochastic Modeling and Non-Intrusive ApproximatioN: Tasmanian v8.2 (development)


|
|
Doxygen
1.9.1
Toolkit for Adaptive Stochastic Modeling and Non-Intrusive ApproximatioN: Tasmanian v8.2 (development)
|
Wrappers to GPU functionality. More...
#include "tsgAcceleratedDataStructures.hpp"
Go to the source code of this file.
Namespaces | |
| TasGrid | |
| Encapsulates the Tasmanian Sparse Grid module. | |
| TasGrid::TasGpu | |
| Wrappers around custom CUDA kernels to handle domain transforms and basis evaluations, the kernels are instantiated in tsgCudaKernels.cu. | |
Functions | |
| template<typename scalar_type > | |
| void | TasGrid::TasGpu::solveLSmultiGPU (AccelerationContext const *acceleration, int n, int m, scalar_type A[], int nrhs, scalar_type B[]) |
| Least squares solver with data sitting on the gpu device. More... | |
| template<typename scalar_type > | |
| void | TasGrid::TasGpu::solveLSmultiOOC (AccelerationContext const *acceleration, int n, int m, scalar_type A[], int nrhs, scalar_type B[]) |
| Identical to TasGpu::solveLSmultiGPU() but the arrays are on the CPU and the MAGMA out-of-core implementation is used. | |
| template<typename scalar_type > | |
| void | TasGrid::TasGpu::solveLSmulti (AccelerationContext const *acceleration, int n, int m, scalar_type A[], int nrhs, scalar_type B[]) |
| Identical to TasGpu::solveLSmultiGPU() but the data starts with the CPU and gets uploaded to the GPU first. | |
| void | TasGrid::TasGpu::factorizePLU (AccelerationContext const *acceleration, int n, double A[], int_gpu_lapack ipiv[]) |
Factorize 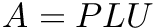 , arrays are on the GPU. , arrays are on the GPU. | |
| void | TasGrid::TasGpu::solvePLU (AccelerationContext const *acceleration, char trans, int n, double const A[], int_gpu_lapack const ipiv[], double b[]) |
| Solve A x = b using a PLU factorization. | |
| void | TasGrid::TasGpu::solvePLU (AccelerationContext const *acceleration, char trans, int n, double const A[], int_gpu_lapack const ipiv[], int nrhs, double B[]) |
| Solve A x = b using a PLU factorization, B is in row-major format. | |
| template<typename scalar_type > | |
| void | TasGrid::TasGpu::denseMultiply (AccelerationContext const *acceleration, int M, int N, int K, typename GpuVector< scalar_type >::value_type alpha, GpuVector< scalar_type > const &A, GpuVector< scalar_type > const &B, typename GpuVector< scalar_type >::value_type beta, scalar_type C[]) |
| Wrapper to GPU BLAS that multiplies dense matrices (e.g., cuBlas, MAGMA). More... | |
| template<typename scalar_type > | |
| void | TasGrid::TasGpu::denseMultiplyMixed (AccelerationContext const *acceleration, int M, int N, int K, typename GpuVector< scalar_type >::value_type alpha, GpuVector< scalar_type > const &A, scalar_type const B[], typename GpuVector< scalar_type >::value_type beta, scalar_type C[]) |
| Identical to TasGpu::denseMultiply() but both B and C are array in CPU memory. | |
| template<typename scalar_type > | |
| void | TasGrid::TasGpu::sparseMultiply (AccelerationContext const *acceleration, int M, int N, int K, typename GpuVector< scalar_type >::value_type alpha, const GpuVector< scalar_type > &A, const GpuVector< int > &pntr, const GpuVector< int > &indx, const GpuVector< scalar_type > &vals, scalar_type C[]) |
| Wrapper to GPU methods that multiplies a sparse and a dense matrix. More... | |
| template<typename T > | |
| void | TasGrid::TasGpu::sparseMultiplyMixed (AccelerationContext const *acceleration, int M, int N, int K, typename GpuVector< T >::value_type alpha, const GpuVector< T > &A, const std::vector< int > &pntr, const std::vector< int > &indx, const std::vector< T > &vals, T C[]) |
| Identical to TasGpu::sparseMultiply() but the sparse matrix and the result C are in CPU memory. | |
Wrappers to GPU functionality.
The header contains definitions of various operations that can be performed on the GPU devices with the corresponding GPU backend.