Components
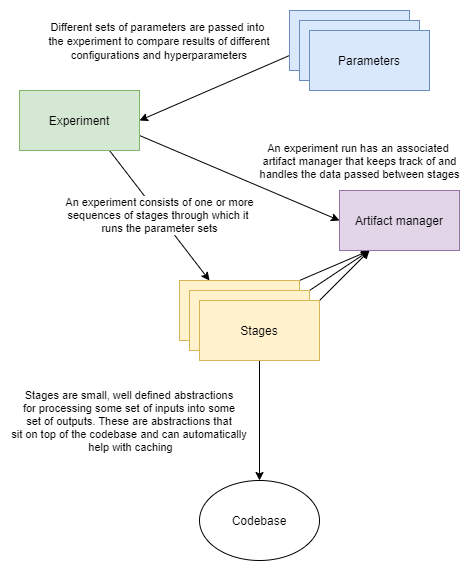
Experiments route parameters into lists of stages, stages route relevant parameters into codebase calls. An artifact manager tracks information from the experiment run and all the data passed between stages.
Stages - A stage is a small, well-defined abstraction for processing some set of inputs into some set of outputs. These abstractions sit on top of the codebase, and can automatically cache outputs.
@stage(...)
def clean_data(...):
# ...
return cleaned_data
Procedures - A procedure is a list of stages to run in sequence for a given parameter set. An example of a procedure might be to load, clean, and split a dataset, and then train and test a model with it. Procedures are defined inside of experiments. Procedures are simply an alternative way to running stages than the functional form.
proc = Procedure([
get_data,
clean_data,
split_data,
train_model,
test_model
], ...)
Parameter sets - Parameter sets represent a collection of configuration values or adjustable parameters for the stage functions to apply to the functions called in the codebase.
Records - A record is a collection of data/variables used in a single run of a procedure with a single parameter set. A record is automatically passed between stages of a procedure in order to persist the information. The currently active record is passed into every stage, so a stage has manual access to everything stored in it.
Artifact Manager - An artifact manager instance is associated with each experiment run, and it tracks and handles all intermediate outputs from the various stages. The manager is the overarching collection of records for an experiment run. It tracks all records for each procedure/parameter set used. A stage with an aggregate decorator can get access to all records instead of just the currently active one in the procedure in order to aggregate results or other data across the records.
Experiments - Experiments apply given parameter sets to one or more procedures, potentially running additional aggregate stages to collect and analyze results from multiple procedure runs across parameter sets. The intention of an experiment is to allow easy comparison of results for multiple similar procedures and/or multiple parameter configurations across one or more procedures.
Component interactions
The below sections describe how the different components interact with and flow through each other.
Stage flow
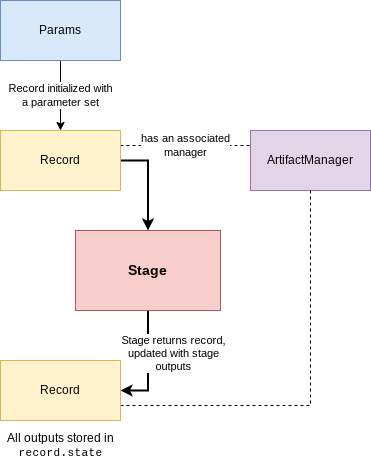
A stage is the processing or transformation of a record. A record has a state attribute, which is a dictionary
of data from previous stages. A stage which requires input automatically finds those input variables from the passed record.state and
passes them into the function,
and the outputs are stored from the function returns back into record.state. A record is initialized with some ExperimentParameters parameter
set, and the record itself has an associated artifact manager.
Note that the four components here, parameters, records, stages, and a manager are the minimum components required to interact with Curifactory. Procedures and experiments are helpful but not required, and you could for instance run stages on their own with just these four components in a jupyter notebook or similar. (However, most of the benefit of Curifactory comes from the experiment management side through the experiment CLI, which minimally requires using experiments as well.)
Procedure flow
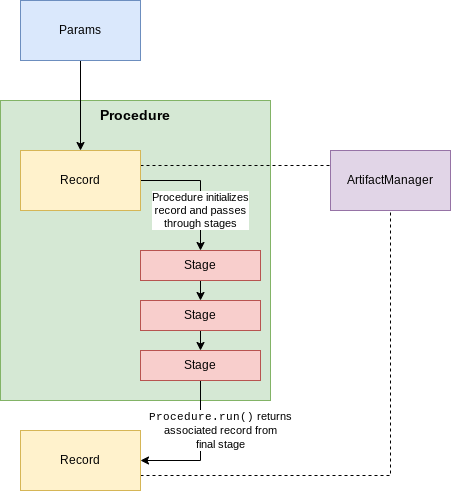
Procedures simplify calling multiple stages. A procedure is defined with a list of these stages, and then
calling proc.run(params) while passing in an ExperimentParameters parameter set will automatically create an associated
record, store it in the manager, and then execute the sequence of stages as a pipeline on the record.
The output is the final record, which could also be accessed as manager.records[-1], since it was the
last record added to the manager.
Note that the run() function optionally takes a record as a parameter, which if passed will use the existing record
rather than creating a new one, meaning multiple procedures can technically be chained.
Any aggregate stages that are applied to a given record must be the first stage in the chain for that record. Similarly, if including an aggregate stage as part of a procedure it must be the first one listed. There are several ways you can control what set of records is passed into an aggregate stage in a procedure:
- If you pass another procedure instance to
previous_proc, it will use all records created from thatprocedure as the input record list for this one. You can directly specify
recordsand provide the desired list of previous records to use.- If neither
previous_procorrecordsis specified, it will grab all existing records from theartifact manager.
proc1 = Procedure([...])
proc1.run(params1)
proc1.run(params2)
proc2 = Procedure([my_aggregate], previous_proc=proc1)
proc2.run(None) # the records created for params1 and params2 will be passed to the aggregate
Experiment flow
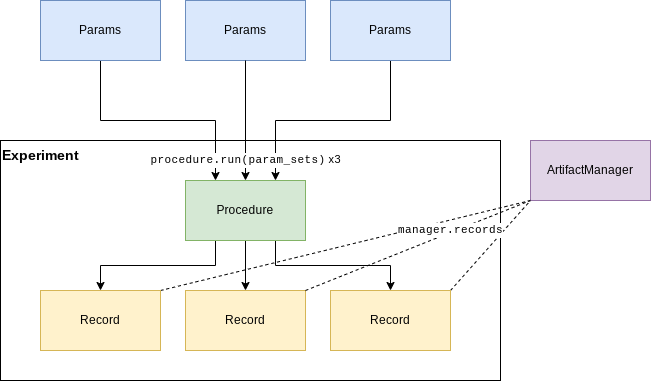
Note that this is a simplified example of an experiment running a single procedure. You can in principle define an experiment run function to be as complex as needed.
An experiment is a relatively free-form way of defining one or more procedures (or manually running stages) to run on any number
of passed parameter sets. The code for an experiment is user-defined, but the Curifactory experiment CLI
expects an experiment script to have a function that takes a list of ExperimentParameters instances and an
artifact manager, and provides many additional tools for working with and getting output from the experiment runs.
Running a procedure on multiple different parameter sets adds a record to the manager for each one. This
allows for comparison between the results by getting the records through manager.records.
Anatomy of a stage
The @stage decorator is placed on every stage function, and this handles passing in the appropriate inputs
from the record, storing new outputs in the record, checking for previously cached outputs (short-circuiting if so),
and caching returned results from the function.
Every stage function is expected to take a Record instance as the first argument. (Procedures automatically handle this.)
The stage will return the modified record rather than the direct output of the function the stage is decorating. The direct
function output can be obtained from record.output on the returned record.
The decorator itself primarily accepts three parameters: inputs, outputs, and optionally cachers.
The inputs and outputs parameters are arrays of strings, where each string is the name of an artifact
(piece of data) to retrieve or store on the record.

The above example shows how decorator parameters interface with the function. The cachers, if specified, direct the stage to store the order-respective output using that type of cacher. When the stage is running, if it sees pre-cached data for all requested outputs, it will load and return those instead of evaluating the function. (Unless overwrite has been specified in the passed arguments.)
Note that caching outputs is all or nothing, you cannot cache only some of them - if any cachers are given, one must be given for every output.
Stage parameters
The functions that a stage wraps always take a record as their first argument. As mentioned in previous sections, input names given in the stage inputs argument must also show up as arguments in the function. The stage wrapper means that you can manually call the stage function while only passing it the record, and the stage will handle populating the remainder of these parameters:
@stage(inputs=["my_input"], ...)
def some_stage(record, my_input):
# ...
some_stage(my_record) # this is valid even though we pass nothing for my_input
The above snippet shows we don’t need to pass (and the point of curifactory is
to not need to pass) anything in for my_input. As long as a key
"my_input" exists on the record’s state, this stage will execute. If the
input key does not exist, a KeyError is raised.
However, in some cases, we may not strictly need a value to be in the state
already, if our computation can gracefully handle it. Like a normal function, we
can specify default values for our parameters in the definition. Note that for
this to work, we must also instruct the stage to ignore missing input keys in
the state, which we do by setting the suppress_missing_inputs flag:
@stage(inputs=["my_input"], ..., suppress_missing_inputs=True)
def some_stage(record, my_input=None):
# ...
some_stage(my_record)
In the above case, the stage will still execute even if my_input does
not exist, and inside the function its value will be None.
We can also directly pass a specific value for an argument when we call a stage,
like we would a normal function. Doing so negates the need for the
suppress_missing_inputs flag, and would override a value from state if
one exists:
@stage(inputs=["my_input"], ...)
def some_stage(record, my_input=None):
# ...
some_stage(my_record, my_input=42)
In this case, my_input inside the stage code will be 42, regardless of
what it is in state (or even if it doesn’t exist in state.)
Aggregate parameters
Functions that an aggregate decorator wraps always take a record as their first argument (the same as a normal stage) and then a list of records as the second argument. This list of records (and thus parameter sets) is what the aggregate is intended to aggregate across.
The inputs argument in the decorator is similar to a regular stage in that you’re requesting
those named artifacts from the state to be populated in the function definition. However, it gets
handled slightly differently since the input “state” is coming from multiple records. Each
input argument in the function definition is populated with a dictionary keyed by each
record that has the requested input in its state, and the associated value is that artifact from
that record.
As an example, assume we have three records:
r0 = Record()
r0.state["model"] = some_model
r1 = Record()
r1.state["model"] = some_other_model
r1.state["results"] = 5.0
r2 = Record()
r2.state["results"] = 6.0
@aggregate(inputs=["model", "results"], outputs=["combined_results"])
def combine_results(record, records: list[Record], model: dict[Record, any], results: dict[Record, float]):
final_results = {}
# we can loop through only the records that have "results" in state
for r, result in results.items():
final_results[r.params.name] = result
# we can cross reference the dictinoaries by record
# so if that record had a model we can check:
if r in model:
associated_model = model[r]
return final_results
combine_results(Record(), [r0, r1, r2])
In the above snippet, the records list will have the three passed records r0, r1, and r2.
The model parameter will only contain two entries, keys for r0 and r1, and results will have
two keys r1 and r2.